一、UniMP [2020]
在半监督节点分类任务中,我们需要学习带标签的样本,然后对未标记样本进行预测。为更好地对节点进行分类,基于拉普拉斯平滑性假设(
Laplacian smoothing assumption),人们提出了消息传递模型来聚合节点邻域的信息从而获得足够的事实(fact)来对未标记节点产生更可靠的预测。通常有两种实现消息传递模型的实用方法:
图神经网络 (
Graph Neural Network:GNN):通过神经网络执行特征传播 (feature propagation)以进行预测。标签传播算法(
Label Propagation Algorithm:LPA):跨graph adjacency matrix的标签传播(label propagation)来进行预测。
由于
GNN和LPA基于相同的假设:通过消息传播进行半监督分类。因此有一种直觉认为:将它们一起使用可以提高半监督分类的性能。已有一些优秀的研究提出了基于该想法的图模型。例如,APPNP和TPN通过将GNN和LPA拼接在一起,GCN-LPA使用LPA来正则化GCN模型。但是,如下表所示,上述方法仍然无法将GNN和LPA共同融入消息传递模型,从而在训练和预测过程中同时传播特征和标签。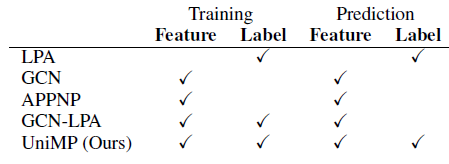
为了统一特征传播和标签传播,主要有两个问题需要解决:
聚合特征信息和标签信息:由于节点特征是由
embedding表达的,而节点标签是一个one-hot向量。它们不在同一个向量空间中。此外,它们的信息传递方式也不同:
GNN可以通过不同的神经网络架构来传播信息,如GraphSAGE、GCN和GAT;但是LPA只能通过图邻接矩阵来传递标签信息。监督训练:用特征传播和标签传播进行监督训练的模型不可避免地会在
self-loop标签信息中出现过拟合,这使得在训练时出现标签泄漏(label leakage),导致预测的性能不佳。
受
NLP发展的启发,论文《Masked label prediction: unified message passing model for semi-supervised classification》提出了一个新的统一消息传递模型(Unified Message Passing: UniMP),并且使用带masked label prediction的UniMP来解决上述问题。UniMP模型可以通过一个共享的消息传递网络将特征传播和标签传播,从而在半监督分类中提供更好的性能。UniMP是一个多层的Graph Transformer,它使用label embedding来将节点标签转换为和节点特征相同的向量空间。一方面,
UniMP像之前的attention-based GNN一样传播节点特征;另一方面,UniMP将multi-head attention视为转移矩阵从而用于传播label vector。因此,每个节点都可以聚合邻域的特征信息和标签信息。即,
label vector的转移矩阵来自于attention,而不是来自于图的邻接矩阵。为了监督训练
UniMP模型而又不过拟合于self-loop标签信息,论文从BERT中的masked word prediction中吸取经验,并提出了一种masked label prediction策略。该策略随机mask某些训练样本的标签信息,然后对其进行预测。这种训练方法完美地模拟了图中标签信息从有标签的样本到无标签的样本的转移过程。
论文在
Open Graph Benchmark:OGB数据集上对三个半监督分类数据集进行实验,从而证明了UniMP获得了SOTA半监督分类结果。论文还对具有不同输入的模型进行了消融研究,以证明UniMP方法的有效性。此外,论文还对标签传播如何提高UniMP模型的性能进行了最彻底的分析。
1.1 模型
定义图
每个节点
每条边
每个节点
one-hot表示为one-hot构成标签矩阵实际上在半监督节点分类任务中,大部分节点的标签是未知的。因此我们定义初始标签矩阵
one-hot标签向量或者全零向量组成:对于标记节点,它就是标签的one-hot向量;对于未标记节点,它就是全零的向量。图的邻接矩阵定义为
degree。归一化的邻接矩阵定义为
特征传播(
Feature Propagation)模型:在半监督节点分类中,基于拉普拉斯平滑假设,GNN将节点特征GNN的特征传播范式为:在第其中:
representation矩阵,final embedding矩阵
标签传播(
Label Propagation)模型:LPA假定相连节点之间的标签是平滑的,并在整个图上迭代传播标签。LPA的特征传播范式为:在第其中
在
LPA中,标签信息通过归一化的邻接矩阵
1.1.1 UniMP 模型
UniMP整体架构如下图所示。我们采用了Graph Transformer并结合使用label embedding来构建UniMP模型,从而将上述特征传播和标签传播结合在一起。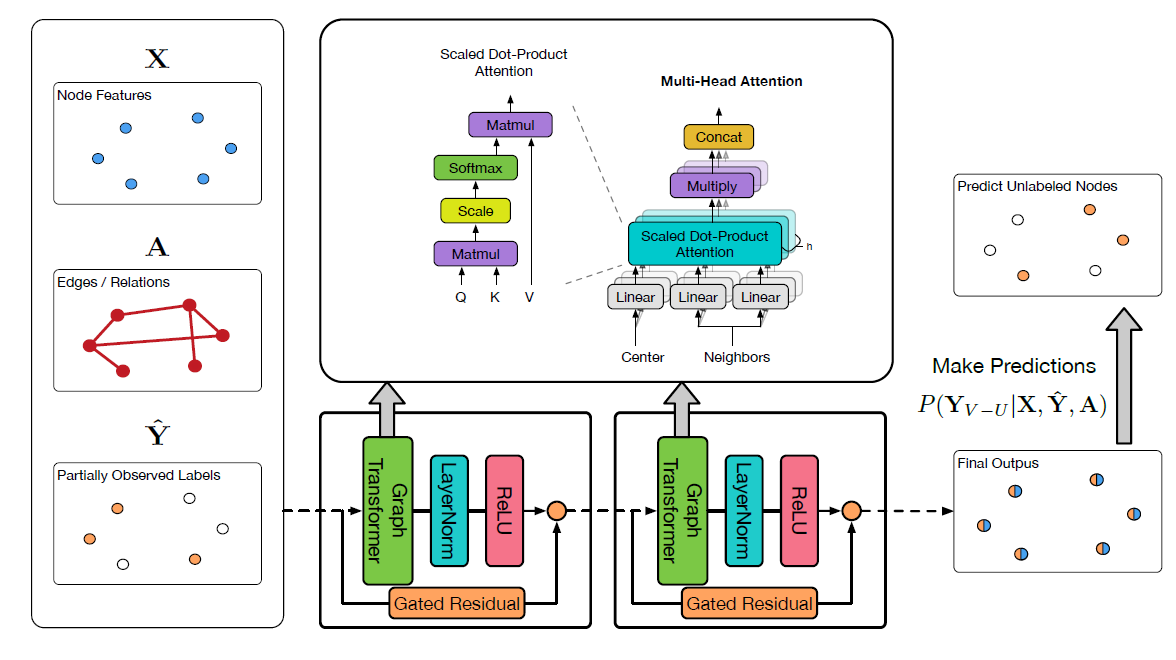
Graph Transformer:由于Transformer已经在NLP中被证明功能强大,因此我们将常规的multi-head attention应用到graph learning中。给定节点
representation集合multi-head attention:其中:
head的隐层大小。head attention。
我们首先将
source featurequery向量distant featurekey向量edge featurekey向量作为额外的信息。编码过程中使用了可训练的参数edge feature跨层共享。在计算注意力系数时,edge feature作为key的附加信息。当得到
graph multi-head attention,我们聚合节点注:这里的公式和上面的架构图不匹配。根据公式中的描述,残差应该连接在
Graph Transformer层之后。即:残差连接 ->LayerNorm->ReLU。其中:
节点
embeddingvalue向量考虑了
和特征传播相比,
multi-head attention矩阵代替了原始的归一化邻接矩阵作为消息传递的转移矩阵(类似于GAT)。另外,我们提出一个层间的门控残差连接(gated residual connection)来防止过度平滑(oversmoothing)。门控机制由
类似于
GAT,如果我们在输出层应用Graph Transformer,则我们对multi-head output应用均值池化(并且没有LayerNorm和relu):Label Embedding and Propagation:我们提出将部分观测到的标签信息embed到节点特征相同的空间中:label embedding向量和未标记节点的零向量。然后,我们通过简单地将节点特征和标签特征相加得到传播特征(
propagation feature):我们可以证明,通过将部分标记的
证明:令
Graph Transformer中的attention矩阵(即edge feature,并且bias向量。那么我们有:其中
APPNP中预定义的超参数。为简单起见,我们取
其中
因此我们发现
UniMP模型可以近似分解为特征传播
1.1.2 Masked Label Prediction
已有的
GNN相关工作很少考虑在训练和推断阶段都使用部分观测的标签。大多数工作仅将这些标签信息作为ground truth target,从而监督训练模型参数其中
但是,我们的
UniMP模型会传播节点特征和标签信息从而进行预测:inference性能很差。我们向
BERT学习,它可以mask输入的word并预测被masked的word从而预训练BERT模型。有鉴于此,我们提出了一种masked label prediction策略来训练我们的模型。训练过程中,在每个iteration,我们随机屏蔽部分节点标签为零并保留剩余节点标签,从而将label_rate所控制(label_rate表示保留的标签比例)。假设被
masked之后的标签矩阵为其中:
masked标签的节点数量,masked标签。每个
batch内的target节点的label都是被屏蔽掉的。否则的话,对target节点预测标签会发生标签泄漏。通过这种方式,我们可以训练我们的模型从而不会泄露
self-loop标签信息。这篇论文就是一篇水文,其思想就是把
node label作为一个节点特征拼接到原始节点特征上去(当然,目标节点拼接全零信息而不是node label从而防止信息泄露),然后在所有输入的特征上执行随机mask。在推断过程中,我们可以将所有
1.2 实验
数据集:和实际工程应用的图相比,大多数论文常用的图数据集规模很小。
GNN在这些论文数据集上的性能通常不稳定,因为数据集太小、不可忽略的重复率或泄露率、不切实际的数据切分等。最近发布的
OGB数据集克服了常用数据集的主要缺点,它规模更大、更有挑战性。OGB数据集涵盖了各种现实应用,并覆盖了多个重要领域,从社交网络、信息网络到生物网络、分子图、知识图谱。它还覆盖了各种预测任务,包括node-level预测、graph-level预测、edge-level预测。因此我们在该数据集上进行实验,并将
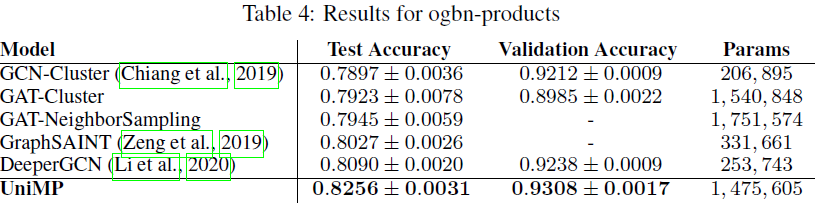
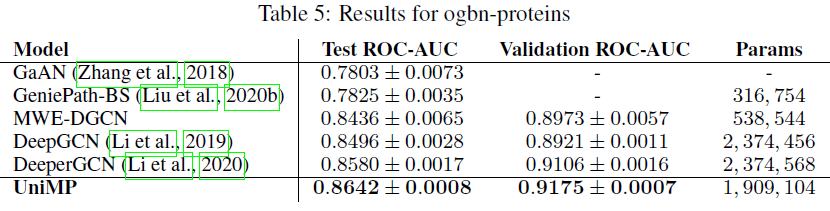
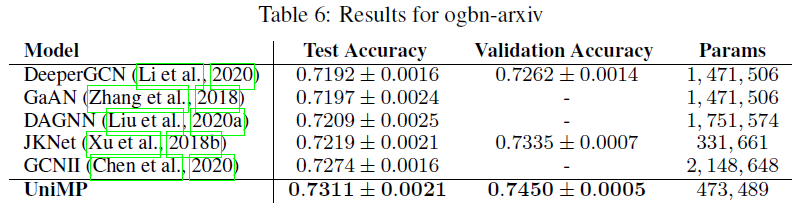
UniMP和SOTA模型进行比较。如下表所示,我们对三个OGBN数据集进行实验,它们是具有不同大小的不同任务。其中包括:ogbn-products:关于47种产品类别的分类(多分类问题),其中每个产品给出了100维的节点特征。ogbn-proteins:关于112种蛋白质功能的分类(多标签二分类问题),其中每条边并给出了8维的边特征。ogbn-arxiv:关于40种文章主题的分类(多分类问题),其中每篇文章给出了128维的节点特征。

实现细节:
这些数据集大小或任务各不相同,因此我们使用不同的抽样方法对模型进行评估。
在
ogbn-products数据集中,我们在训练期间每一层使用size=10的NeighborSampling来采样子图,并在推断期间使用full-batch。在
ogbn-proteins数据集中,我们使用随机分区(Random Partition)将稠密图拆分为子图,从而训练和测试我们的模型。训练数据的分区数为9、测试数据的分区数为5。在小型的
ogbn-arxiv数据集中,我们对训练数据和测试数据进行full batch处理。
我们为每个数据集设置了模型的超参数,如下表所示。
label rate表示我们在应用masked label prediction策略期间保留的标签比例。我们使用
lr=0.001的Adam优化器来训练模型。此外,我们在小型ogbn-arxiv数据集中将模型的权重衰减设置为0.0005来缓解过拟合。所有的模型都通过
PGL以及PaddlePaddle来实现,并且所有实验均在单个NVIDIA V100 32 GB上实现。

实验结果:
baseline方法和其它SOTA方法均由OGB排行榜给出。其中一些结果是原始作者根据原始论文官方提供,其它结果由社区重新实现的。并且所有这些结果都保证可以用开源代码复现。按照
OGB的要求,我们对每个数据集运行10次实验结果,并报告均值和标准差。如下表所示,我们的UniMP模型在三个OGBN数据集上都超过所有其它模型。由于大多数模型仅考虑基于特征传播来优化模型,因此结果表明:将标签传播纳入GNN模型可以带来重大改进。具体而言:
UniMP在gbn-products中获得了82.56%的测试准确率,相比SOTA取得了1.6%的绝对提升。UniMP在gbn-proteins中获得了86.42%的测试ROC-AUC,相比SOTA取得了0.6%的绝对提升。UniMP在gbn-arxiv中获得了73.11%的测试准确率,相比SOTA实现了0.37%的绝对提升。
作者没有消融研究:
不同
label_rate对于模型性能的变化(当label_rate = 0时表示移除标签传播)。除了
Graph Transformer之外,UniMap采用其它base model的效果是否也很好。